八巻研の研究内容
<バックグラウンド:ネットワーク機器とレイヤ7解析>
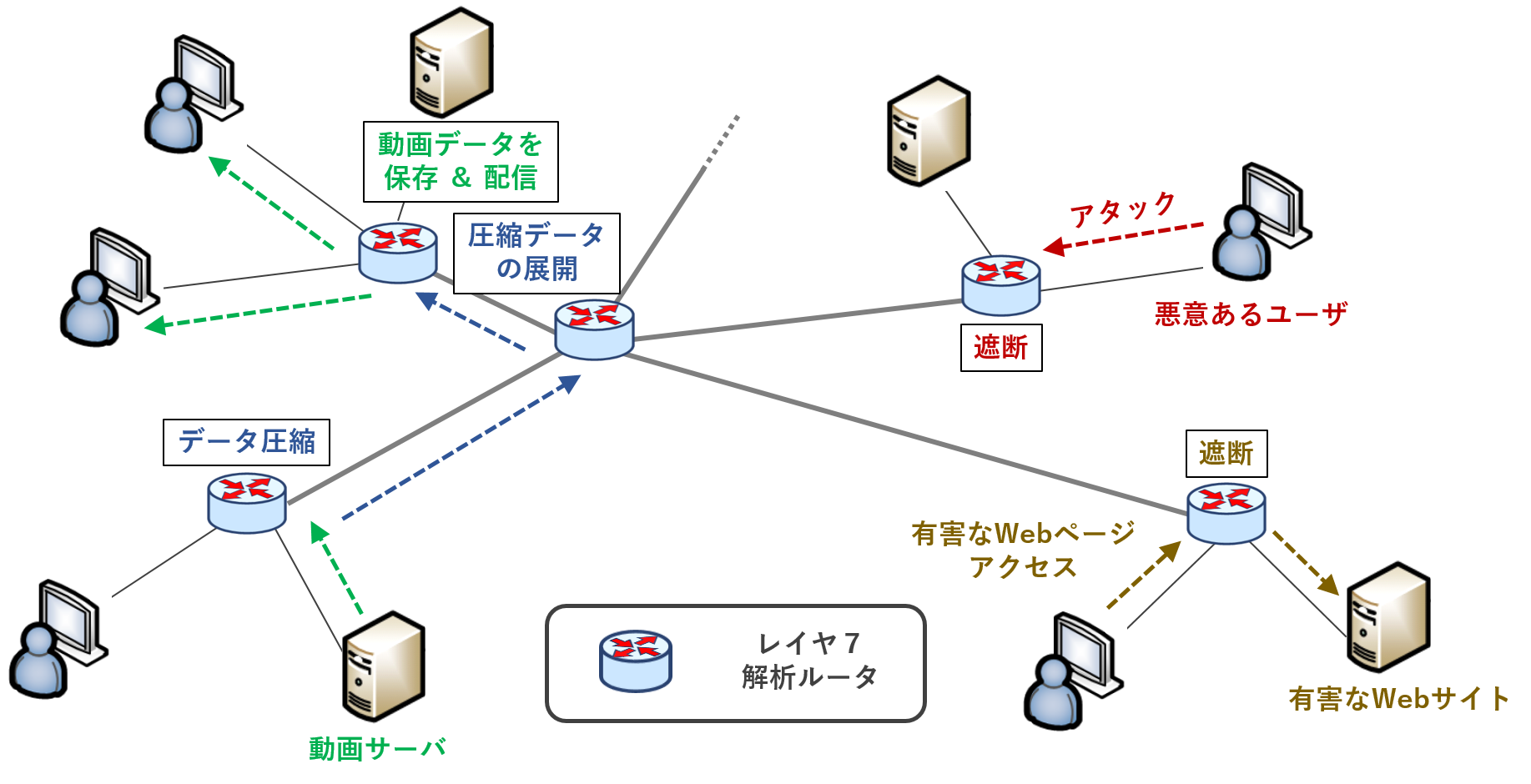
八巻研において研究のコアとなる部分は”ネットワーク機器”と”レイヤ7解析”です. ここで言うネットワーク機器とは,ルータやスイッチ,ネットワーク侵入検知システム等,皆さんの端末が通信する際にその途上に位置する(特に意識せずに通過する)機器たちです. そしてレイヤ7というのは,webページや動画データ,メールデータのように通信内容本体を表すデータ部分です(もちろんログインIDやパスワードなども含む).まず,従来のルータやスイッチはレイヤ7までデータを見ることはありません. 通信パケットの宛先IPアドレスを見て,適切なポートから送り出す,という役割のみを担うからです. しかしながら,近年のインターネットでは,ネットワーク(機器)により高度な役割が求められています.
例えば,音声やVRのようなリアルタイム性の高いサービスでは,通信の遅延や揺らぎがサービス品質に直結することから低遅延で揺らぎの小さい通信を確立する必要があります. 他方で,動画サービスなどは超大容量の動画データにより回線を逼迫することから,他のサービスの通信が妨げられないよう使用帯域を適切に制御する必要があります. また,近年はIoTのセンサデバイスやロボット遠隔操作など,十分なセキュリティ対策機能を持たない端末が増えており,このような端末には安全な通信を確立する必要があるでしょう.
このように,これからのインターネットには,アプリケーションに応じた適切な制御が求められます. そのためには,ネットワーク機器がレイヤ7,すなわち通信内容まで把握する必要があるわけです. 通信内容まで把握したネットワーク機器に何が出来るのか?何が問題となるのか? そんな次世代インターネットの形を模索するのが八巻研です.
<INTを用いたネットワークアプリケーションの検討>
近年,INT(In-band Network Telemetry)と呼ばれる技術が注目されています. この技術では,ルータにおいて,通過するパケットに通信内容とは直接関係のないメタデータ(どんなデータでも良い.helloでも今日の日付でも)を付与します. このメタデータを上手く使うと,以下のようにネットワークで様々なことが出来るようになります.
経由地制御
基本的に,インターネットではパケットに指定できる宛先は最終到着地1つです. 途中の経路を指定することはできません. ですが,メタデータとして,そのパケットの経由地リストを付与することで,途中経路まで指定することが可能です. これにより,同じ宛先であっても,通信により経路Aと経路Bを使い分けることや,怪しいパケットのみ精査サーバを経由させるといった,きめ細かい経路制御が可能となります.
経路証明
パケットがルータを通過する毎にそのルータの署名をメタデータに追加してみます. そうすると,パケットのメタデータを覗くことで,そのパケットが通ってきた道筋を確認することができます. インターネットでは,なりすましやフィッシングサイトなど,通信するつもりだったところとは違うところからデータがやってくることがあります. その際に,パケットの経路が証明できれば安全性が高まります.
混雑度推定
面白い使い方としてネットワークの混雑度推定なんかもあります. この用途では,パケットがルータを通過する際に,そのルータでの時刻情報(Timestamp)をメタデータに追加します. 例えばパケットがルータ1→ルータ2と通過する際にT1,T2の時刻情報をパケットに付与します. これらの時刻の差分を取ると,(正確ではないですが)ルータ間の転送にかかった遅延が算出できます. この遅延を都度測定してモニタリングすることで,ルータ間の回線混雑度を把握することができます. ルータ間の回線の混雑具合により転送にかかる時間が上下するためです.
このように,INTは多くの可能性を秘めた興味深い技術ですが,まだ登場から日が浅く,INTを用いたアプリケーションについては検討の余地があります. 皆さんと私でぜひINTの未来を考えてみたいと思います.
<ネットワーク侵入検知システムNIDSの検査性能向上>
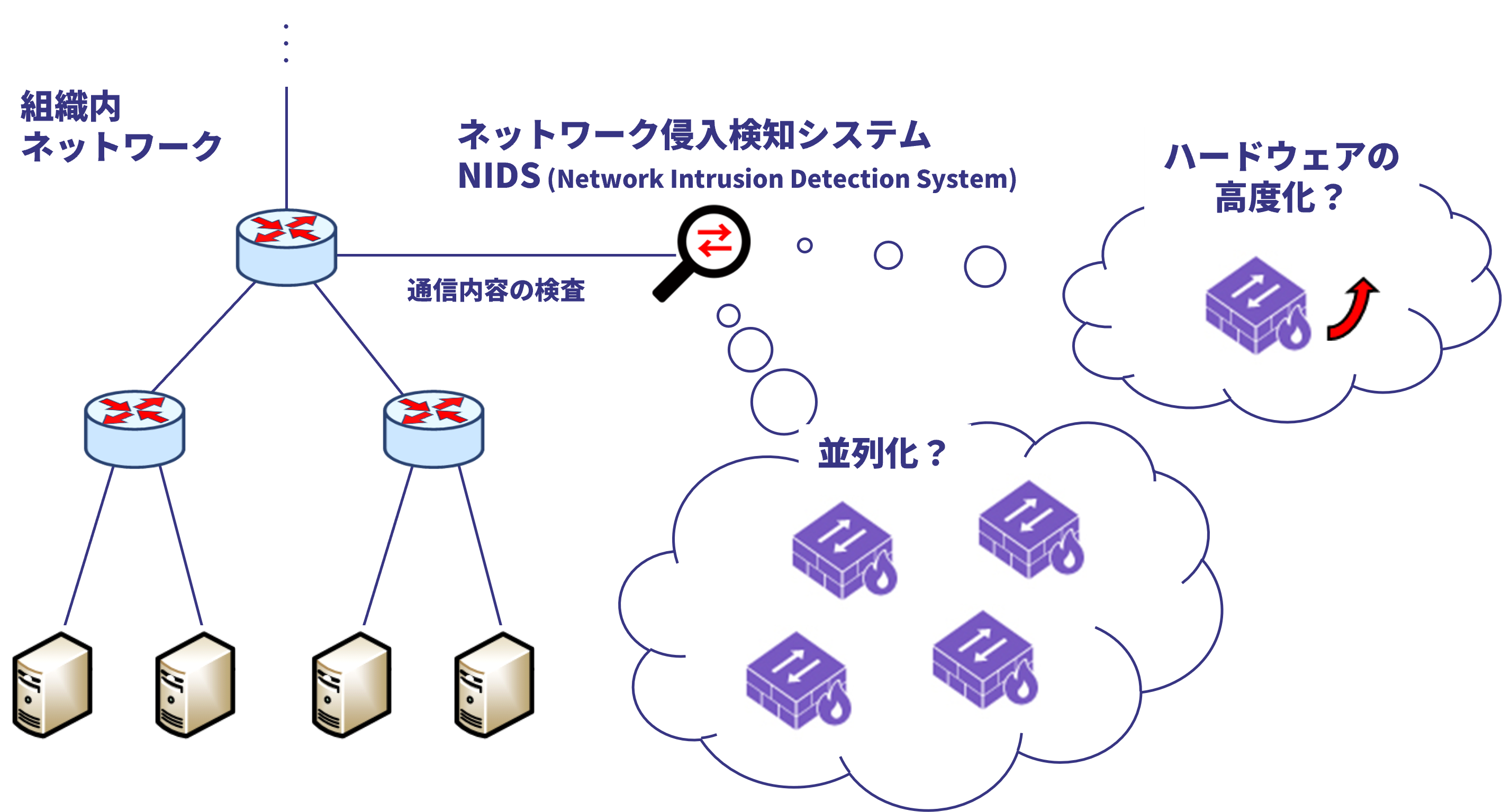
近年のインターネットにおいて,セキュリティの確保は最重要課題となっています. なぜなら昔とは違い,現代のインターネットには無数の個人情報が飛び交っているからです. 銀行口座のアカウントをハックされでもしたら目も当てられません. 今後,超スマート社会(Society 5.0)が実現されていくと,ロボットの遠隔制御,車の自動運転,遠隔での医療,IoTセンサの制御等,様々なスマートシティサービスがインターネットを介して提供されます. インターネットのセキュリティが重要どころか,人命に直結していくことも想像に難くありません.ネットワーク侵入検知システム(NIDS: Network Intrusion Detection System)はネットワーク内に設置し,そのネットワークを流れる通信トラフィックを監視・検査する機器です. たとえ,ネットワーク内に脆弱なセンサデバイスが存在したとしても,NIDSによりそのネットワーク全体の通信が完全に検査されるならば安全です. NIDSは現在多くの組織ネットワークにおいて導入されている重要なネットワーク機器です(もちろん本学にも導入されています).
NIDSの課題は検査性能と価格です. ネットワーク内の全通信内容を検査するわけですから,とんでもない量のパケットに対してとんでもなく大変な検査(多量のウィルスパターンの照合等)をしなければなりません. もちろん,そんなにすごい機器は価格も高いです. 今時のネットワークは速いところでは100Gbps~の回線を持っていますが,10Gbpsの検査性能を持つNIDS機器でさえ購入するには数千万円します. 要するに,高価すぎる上に,そもそも検査性能が足りていないのです. 八巻研では,このようなNIDSの課題の解決を目指しています.
<レイヤ7解析ルータにおける文字列探索処理の高速化>
レイヤ7解析ルータの処理は重く,近年の高速なネットワークで実用するには10倍~100倍程度も処理速度が足りていないのが現状です. 処理性能向上のボトルネックとなっている処理に,パケットに対する文字列探索処理があります. 従来のパケット処理では,データの先頭から何Byte目に宛先IPアドレスが入っている,というように必要な情報がどこに含まれているかがわかっていたため,高速な処理が実現できました. しかし,例えばウィルスが何Byte目に入っているか,メールの何文字目に有害なURL情報が含まれているか,決まっているでしょうか? この問題を解決するためには,ウィルスだと判断できるデータ列や有害なURLを,パケットの先頭から一文字ずつマッチングさせていくしかありません. すなわち,”virus”という文字列を検出するには,データの先頭から”v”を探し,”v”が見つかったら次の文字が”i”かどうか判定し…,という動作を繰り返します. そして,この処理こそがレイヤ7ルータにおいて最も時間のかかる処理となります.
これに対し,八巻研ではなるべく上記のような文字列探索をさせないことで文字列探索を高速化する様々なアプローチを提案しています. 一つのアプローチとして,文字列ではなくハッシュ値と呼ばれる数値によりマッチングを行う手法があります. ”virus”という文字列に対しハッシュ値計算を行うと,例えば12という数値が結果として得られます. 同様に,パケットデータから5文字を取りハッシュ値計算を行います. ここで計算結果が12となった場合には,その5文字が”virus”である可能性があるということです. 逆に言えば,計算結果が12とならない場合は,確実に”virus”ではないと言えます. この手法は,検出すべき文字列パターン数が多くなるほど効果的です.

また,別のアプローチとして,そもそも文字列探索をする必要のないデータ部分に対し探索処理をしないという手法があります. インターネット上を流れるデータは様々ですが,例えば動画データ本体やIP電話の音声データにまで文字列探索を行う必要はありません. また,メールや画像等のデータにまで,webサーバの脆弱性を突いたアタックパターンを検出する必要もありません. このように,通信データの内容を知ることができれば,それに応じた検出パターンを適切に選んで適用することが可能となります.
<通信経路上におけるHTTP圧縮通信データの高速展開機構>
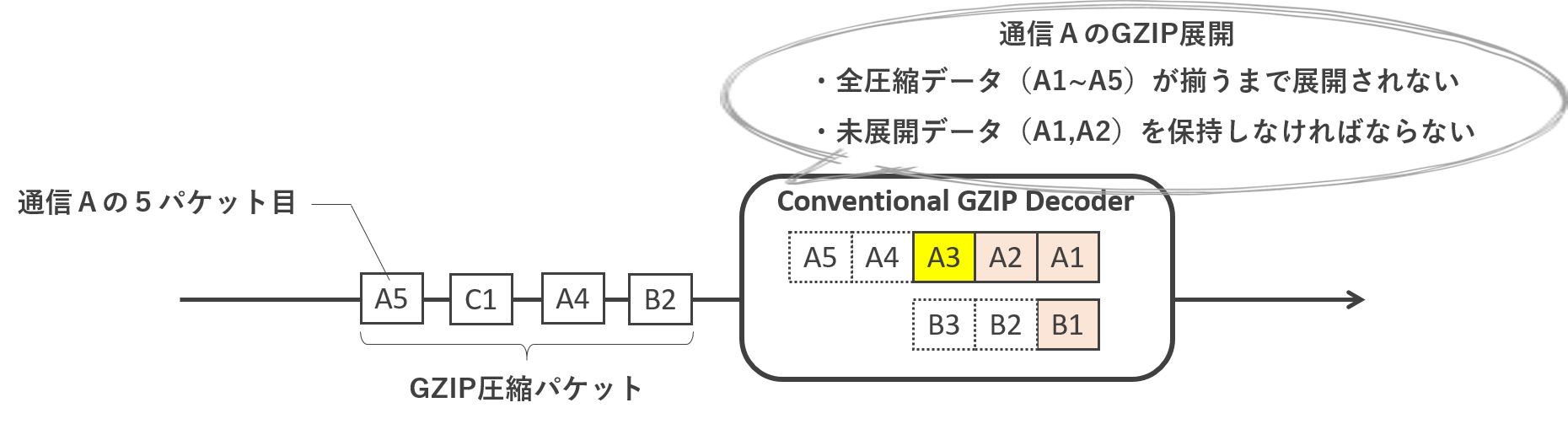
近年,インターネット通信において通信データの圧縮技術が注目されています. というのも,ネットワークトラフィック量はここ3年で2倍に増大と,急激な速度で成長しています. そこで,通信の始点において通信データを圧縮し,終点において圧縮データを展開することで,ネットワーク上を流れるトラフィック量の削減が期待できます. 現在では,我々がwebページを見る際に用いるHTTPにおいても,webコンテンツをGZIP化して転送する機能がデフォルトとなりつつあります.しかしながら,ネットワーク機器においては,データが圧縮されているとその内容が解析できなくなるため厄介です. ネットワーク機器上において,圧縮されたデータを一旦展開する必要があります. …と簡単に言いましたが,ネットワーク経路上では,圧縮データが複数のパケットに分割された状態で流れます. 従って,圧縮データを展開するには,圧縮データを含んでいる全てのパケットを保持し,圧縮データ末尾のパケットの到着まで待たなければなりません. これでは,展開にとても時間がかかりますし,圧縮データを蓄える膨大なメモリが必要となります. そこで八巻研では,少ないメモリ容量で,なおかつ圧縮データが揃うのを待つことなく,到着パケットを逐次に圧縮展開できる専用ハードウェアを提案しています.
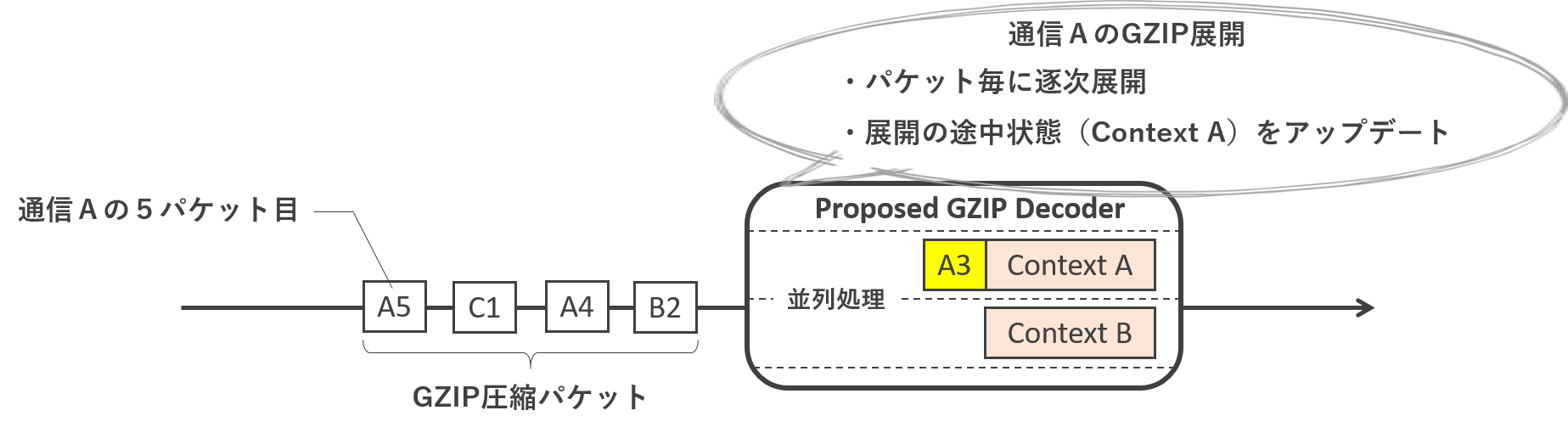
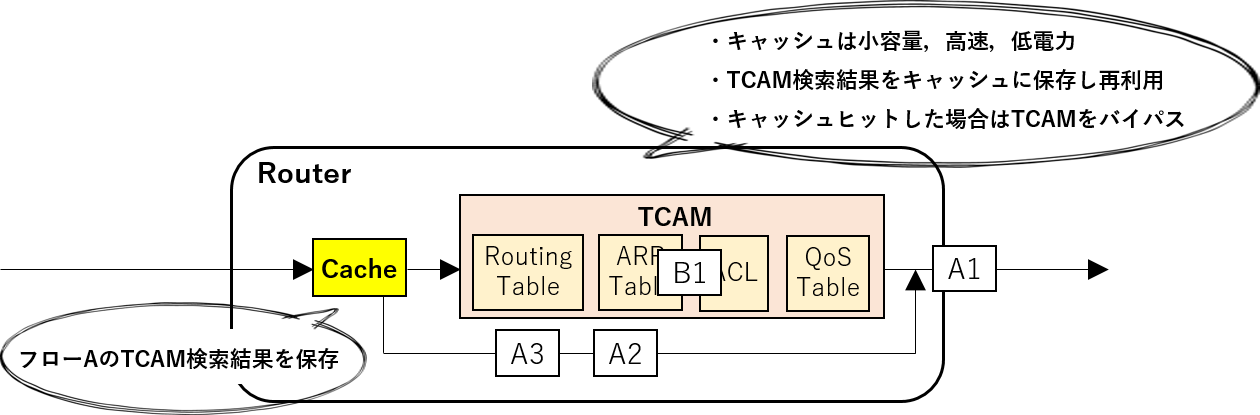
<フロー処理キャッシュを用いたパケット処理の高速化および省電力化>
近年,全てのモノがインターネットに繋がるというInternet of Things(IoT)や,膨大なサイズのデータを扱うビッグデータ解析という言葉が科学技術研究者や企業の界隈においてキーワードとなっています. これらの実現に伴い,通信データ量が今後爆発的に増加する情報爆発が起こると予測されています. 私たちがインターネットを利用するとき,必ず通信データはルータを通過し,正しい宛先へ転送されていきますが,ルータはこの情報爆発に耐えられるのでしょうか? 答えは,処理速度的に見ても,消費電力的に見ても,”危うい”です.
インターネットにおいてデータはパケットという小さいデータ単位で送られてくるため,ルータはパケット毎に処理を行いますが, この時,各パケットの処理に必要な情報はメモリから読み出します. 例えば,パケットの宛先IPアドレスを基に送り出すポートを決定するルーティングテーブルや,パケットに対してファイアウォールを行うフィルタリングテーブル,パケットの転送優先度を決定するQoS(Quality of Service)テーブル等, 複数のテーブルを1パケット毎に読み出すことで,ルータは処理に要する情報を得てパケットを処理します. ここで,現在のハイエンドなルータはTernary Content Addressable Memory(TCAM)と呼ばれる,データエントリ検索の非常に速い特殊なメモリにテーブルを格納することで,高速なパケット処理を実現しています. しかしながら,TCAMは一般的なSRAMメモリ等に対して16倍程高消費電力と言われ,また,その速度も現在のインターネットの最大帯域である100Gbpsで限界が見えてきたと言われています.
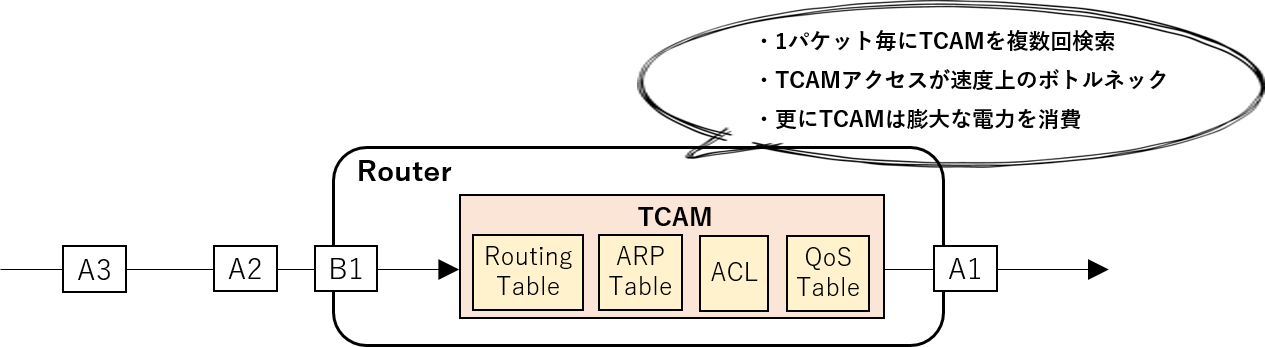
これに対し本研究室では,小規模な分,高速かつ低消費電力なキャッシュメモリにパケット処理結果を保存し,その処理結果を他のパケットでも使い回そうというアプローチを試みています. パケットを一つの通信(例えばブラウザであるwebページを見た際の片方向の通信)や一つの送信元IPアドレスといった,何かしらでまとめた単位をフローと定義します. この時,同じフローに属するパケットの多くのテーブル検索結果は等しくなります. そこで,フローの初回パケットのみ,TCAMで処理し,後続パケットはキャッシュにより処理することで,パケット処理の大幅な高速化と省電力化が可能となります. 特に,フローとして送信元IP・宛先IP・送信元ポート番号・宛先ポート番号・プロトコル番号の5タプルによりフローを定義することで,ほとんどのテーブル検索結果はフローで単一に決定できます.