エクサスケールにおける並列アプリケーション性能解析基盤
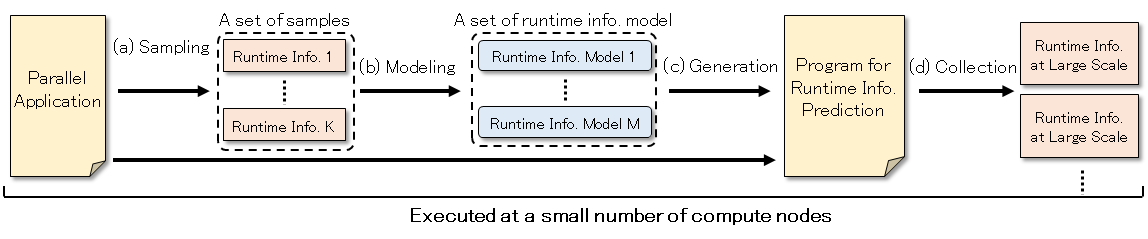
スーパーコンピュータのシステム規模が増大し,その上で動作するアプリケーションの複雑さが増すにつれて,並列アプリケーションの動的な振る舞いを把握するのが難しくなっています.並列アプリケーションの性能解析にはプロファイリングやトレーシングなどの方法が一般に利用されていますが,アプリケーションの動的な振る舞いに関する情報を上記の方法で取得するためには解析対象のアプリケーションを解析対象のシステムで実際に実行する必要があり,大規模なアプリケーションの性能解析には向いていません.当研究室では,解析対象のアプリケーションを小規模実行することによって得られた情報から大規模実行時に得られるであろう情報を予測(実行時情報予測)し,この情報を並列アプリケーションの性能解析に利用する方法を研究しています.本研究は科学研究費補助金基盤研究(B)の支援のもとに行っています.
代表的な研究成果
- S. Miwa, I. Laguna, and M. Schulz, PredCom: A Predictive Apporoach to Collecting Communication Traces, IEEE Transactions on Parallel and Distributed Systems, Vol. 32, Issue 1, pp.45-58 (2021).
- 岡田 悠希,三輪 忍,八巻 隼人,本多 弘樹, MPIにおける小規模実行時の通信トレース解析による大規模実行時の通信タイミング予測の評価, 情報処理学会研究報告 2021-HPC-182, No.16, pp.1-8 (2021).
- 長谷川 健人,有馬 海人,三輪 忍,八巻 隼人,本多 弘樹, MPIアプリケーションのキャッシュプロファイル予測, 情報処理学会研究報告 2021-HPC-178, No.20, pp.1-8, (2021) .
- 有馬 海人,長谷川 健人,三輪 忍,八巻 隼人,本多 弘樹, MPIアプリケーションの関数コール回数予測, 情報処理学会研究報告 2021-HPC-178, No.19, pp.1-7, (2021) .
高性能計算機システムにおける電力管理方式
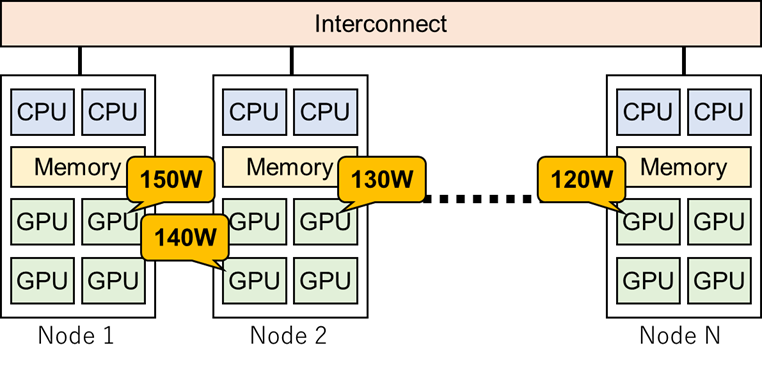
将来のスーパーコンピュータは30MW程度の電力制約のもとでエクサフロップス(浮動小数点演算を1秒間に1,000,000,000,000,000,000回)を超える演算性能を実現することが求められています.このような高い電力効率を実現するためには,CPU,GPUなどのアクセラレータ,メモリ,ネットワークなどのさまざまなデバイスの電力効率を高める必要があります.特に,CPUやGPUなどの半導体チップには製造ばらつきに起因する消費電力のばらつき(電力ばらつき)が存在することが知られており,この電力ばらつきを上手く利用することでシステムは同じ仕事をより少ない消費電力で行うことができるようになります.当研究室では,実運用中のスパコンにおける電力ばらつきの評価と省エネルギー化のための資源割り当てアルゴリズムの開発を行っています.本研究は,KDDI財団の助成のもと,東京工業大学学術国際情報センターと共同で行っています.
代表的な研究成果
- K. Yoshida, R. Sageyama, S. Miwa, H. Yamaki, and H. Honda, Analyzing Performance and Power-Efficiency Variations among NVIDIA GPUs, The 51st International Conference on Parallel Processing (ICPP) (to appear) (acceptance rate: 84/311=27%).
- 小野 賢人,吉田 幸平,三輪 忍,坂本 龍一,八巻 隼人,本多 弘樹, CPUおよびGPUの電力ばらつきを考慮したジョブスケジューリング手法の提案, 情報処理学会研究報告 2022-HPC-185, No.20, pp.1-8 (2022).
- 吉田 幸平,三輪 忍,八巻 隼人,本多 弘樹, CUDAバージョンの違いがカーネルの実行時間と消費電力に与える影響の分析, 情報処理学会研究報告 2021-HPC-183, No.16, pp.1-8 (2022).
- 提山 春日,吉田 幸平,三輪 忍,八巻 隼人,本多 弘樹, Wisteria/BDEC-01におけるNVIDIA A100 GPUの電力性能ばらつきの評価, 情報処理学会研究報告 2021-HPC-182, No.3, pp.1-9 (2021).
次世代半導体デバイスを利用したプロセッサアーキテクチャ
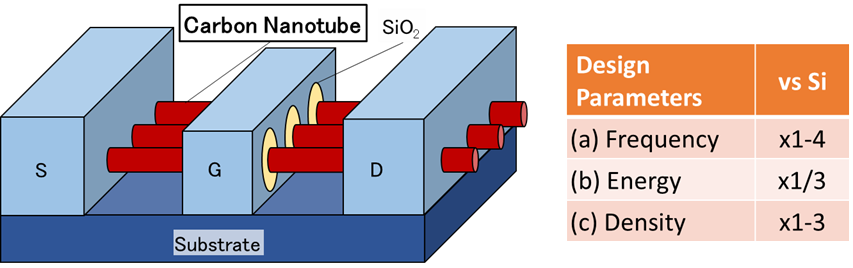
現在のプロセッサの多くはシリコントランジスタによって製造されており,シリコントランジスタの微細化とともにその性能を向上させてきました.しかし,長年の微細化によってトランジスタの各部の大きさはナノメートル規模にまで縮小し,その結果として更なる微細化が困難となりつつあります.シリコントランジスタの微細化に依存しないプロセッサの性能向上手段としてカーボンナノチューブトランジスタと呼ばれる次世代半導体デバイスが注目を集めており,当研究室ではカーボンナノチューブトランジスタを用いたプロセッサの設計技術とアーキテクチャの開発を行っています.東京大学と共同で研究を行っています.
代表的な研究成果
- C. Shi, S. Miwa, T. Yang, R. Shioya, H. Yamaki, and H. Honda, CNFET7: An Open Source Cell Library for 7-nm CNFET Technology, The 28th Asia and South Pacific Design Automation Conference (ASP-DAC) (to appear) (acceptance rate: 102/328=31%).
- 関川 栄一郎,三輪 忍,ヨウ ドウキン,塩谷 亮太,八巻 隼人,本多 弘樹, SRAM の電力/遅延シミュレータCACTIのCNFETへの対応, 情報処理学会研究報告 2022-ARC-249, No.6, pp.1-8 (2022).
- C. Shi,K. Sasaki, S. Miwa, T. Yang, R. Shioya, H. Yamaki, and H. Honda, Evaluation of Microprocessors Placed-and-Routed with CNFET, 情報処理学会研究報告 2021-ARC-248, No.5, pp.1-6 (2022).
- 佐々木 魁,三輪 忍,ヨウドウキン,塩谷亮太,八巻 隼人,本多 弘樹, カーボンナノチューブトランジスタを用いて論理合成したプロセッサの電力/面積/回路遅延評価, 情報処理学会研究報告 2021-ARC-245, No.4, pp.1-7, (2021).
安全かつ高性能な計算環境実現のためのフレームワーク
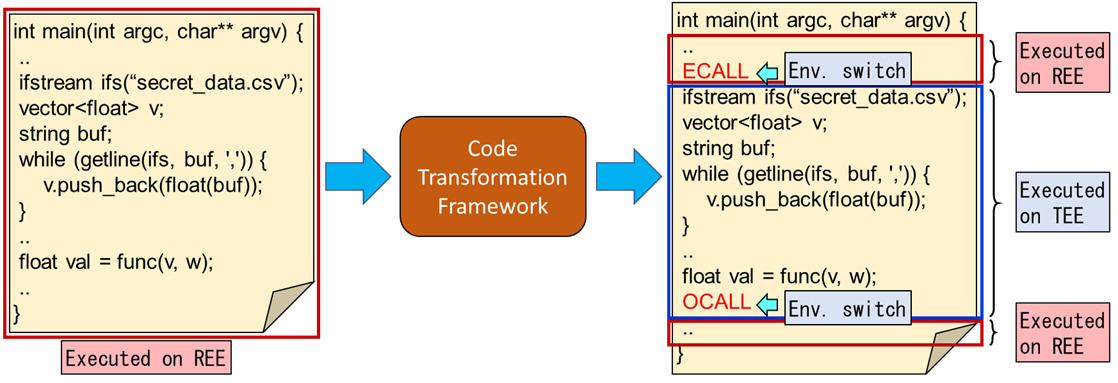
Society5.0を支えるICT基盤として,これまでにない安全性と高い性能を兼ね備えた計算機システムが必要とされています.安全な計算環境としてTEE(Trusted Execution Environment)が存在しますが,TEE上での計算は通常の計算環境(Rich Execution Environment.略してREE)上での計算よりも遅いため,安全性と高性能を高いレベルで両立するためにはアプリケーション内の真に秘匿すべき計算のみをTEE上で実行し,それ以外の計算をREE上で実行するようにプログラミングする必要があります.このようなプログラミングのコストを低減するため,当研究室ではREE用に記述された並列アプリケーションコードからTEE実行すべき処理を自動抽出し,REEとTEEのハイブリッド実行を行うコードを自動生成するコード変換フレームワークを開発しています.本研究はJSTさきがけの研究領域「社会変革に向けたICT基盤強化」の研究課題として実施しています.